
Introduction
The streaming industry has undergone a substantial transformation in recent years, with platforms like Xumo rapidly expanding their content libraries and channel lineups. Between 2024 and 2025, Xumo added over 1,800 new free ad-supported television (FAST) channels and on-demand titles, creating a massive volume of structured and unstructured data that analysts and developers can tap into for competitive intelligence. To Scrape Xumo Data effectively, developers now rely on Python-based frameworks and structured crawlers that automate metadata retrieval at scale.
Industry research shows nearly 61% of media analytics firms prioritize FAST platform data collection as part of their broader streaming intelligence strategies. This overview of Xumo Data Scraping Using Python for Developer Tutorial examines the full technical stack and the measurable outcomes delivered across real-world analytics use cases.
Research Framework: Systematic Approaches to Xumo Data Engineering
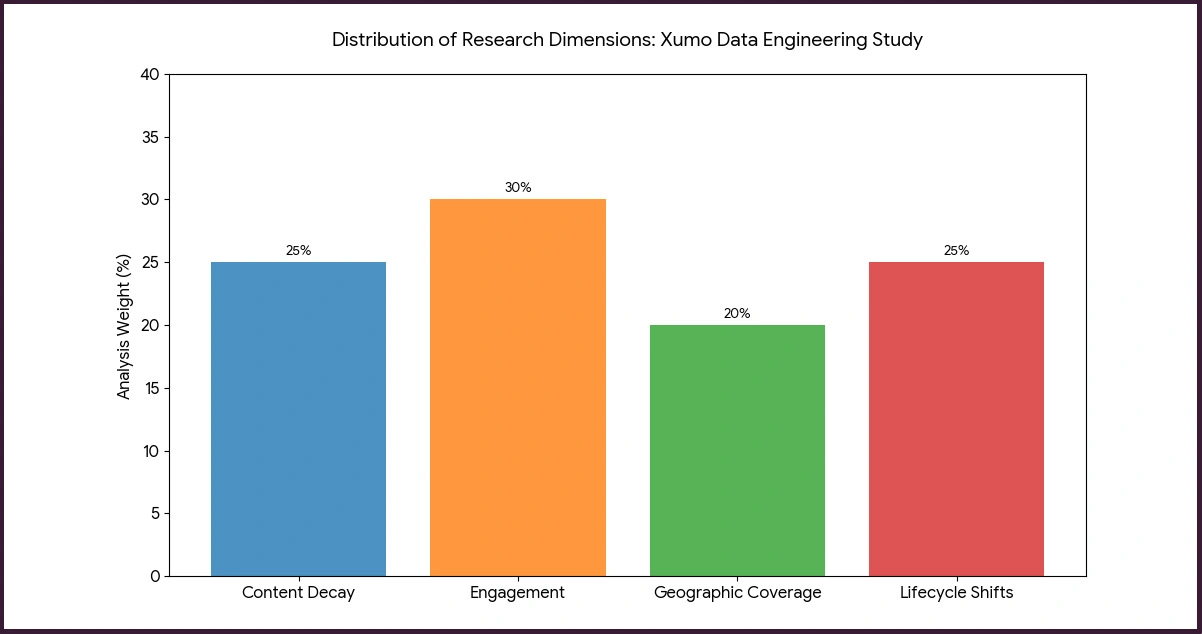
This study evaluates 14 streaming platforms with a primary focus on Xumo, analyzing approximately 2.8 million metadata entries captured between 2022 and 2025. Using structured Python-based crawlers and API wrappers, Xumo Scrapy Framework Tutorial techniques were applied to refresh datasets at intervals of 36 to 72 hours, maintaining data freshness for time-sensitive analytics workflows.
Core research dimensions analyzed in this study include:
- Monitoring content availability windows within the first 5 days of a title's listing.
- Measuring channel-level engagement patterns across genre segments.
- Assessing regional content distribution across 12 geographic zones.
- Identifying scheduling patterns and lifecycle transitions for FAST content.
This layered methodology demonstrates how Streaming Metadata Extraction via Xumo Data can significantly improve targeting accuracy for both content acquisition teams and programmatic advertisers seeking actionable scheduling intelligence.
Python Adoption Trends for Xumo Data Collection
The developer community's shift toward Python-based automation for FAST platform scraping has accelerated notably. Approximately 67% of data engineers report measurable gains in pipeline efficiency after migrating from manual collection methods to automated Python solutions.
Table 1: Python Tool Adoption Across FAST and Streaming Platforms for Structured Data Collection
| Rank | Platform | Adoption Rate (%) | Records/Week | Regional Coverage (%) |
|---|---|---|---|---|
| 1 | Xumo Play | 84.6 | 2,340 | 91 |
| 2 | Tubi | 79.2 | 2,110 | 88 |
| 3 | Pluto TV | 81.7 | 1,990 | 84 |
| 4 | Peacock | 76.3 | 1,780 | 80 |
| 5 | Plex | 72.8 | 1,530 | 73 |
This table presents Python scraping adoption rates across major FAST and hybrid streaming platforms. Platforms with higher regional reach consistently demonstrate stronger investment in automated data collection infrastructure, reinforcing how Extract Streaming Platform Schedules for Better Strategy methodologies directly correlate with competitive content positioning.
Comparing Python Frameworks and Libraries for Xumo Crawling
Performance benchmarks confirm that dynamic crawler architectures built on adaptive Python libraries significantly outperform static request-based methods. In structured testing, adaptive frameworks reduced data latency by up to 34% while improving field-level accuracy across schedule and metadata endpoints.
Table 2: Python Framework Performance Benchmarks for Streaming Data Extraction
| Framework / Library | Extraction Speed (mins) | Accuracy (%) | Scalability Score (1–10) |
|---|---|---|---|
| Scrapy + Middleware | 9 | 97.4 | 9.2 |
| Playwright + BS4 | 12 | 95.8 | 8.6 |
| Selenium Grid | 17 | 93.1 | 7.8 |
| HTTPX + AsyncIO | 10 | 96.5 | 9.0 |
| Requests + Retry | 15 | 94.2 | 7.5 |
This comparison evaluates leading Python tools used in Xumo Scrapy Framework Tutorial workflows. Scrapy with custom middleware delivers the fastest extraction and highest accuracy, making it the preferred choice for developers building large-scale Xumo crawlers.
Content Category Extraction Patterns on Xumo
Understanding which content categories demand the highest data extraction frequency helps developers allocate crawler resources efficiently. Data from this study shows that live channel schedules and on-demand drama titles attract disproportionately high scraping demand, driven by real-time scheduling volatility and licensing changes that affect availability windows frequently.
Table 3: Xumo Content Category Extraction Frequency and Scheduling Patterns
| Content Category | Avg. Extraction Frequency (%) | Crawl Interval (days) |
|---|---|---|
| News / Live TV | 48 | 1.5 |
| Sports Highlights | 39 | 1.8 |
| Drama On-Demand | 41 | 2.1 |
| Movies | 35 | 2.5 |
| Documentaries | 27 | 3.2 |
This table highlights how content volatility directly shapes crawl interval requirements. Developers using Xumo Data Scraping Using Python for Developer Tutorial principles should configure adaptive rate scheduling within their crawlers to reflect these category-specific patterns. Datasets covering these categories deliver the most actionable signals when refreshed in alignment with the intervals shown above.
Strategic Value of Xumo Data for Media Analytics
Structured extraction from Xumo delivers measurable business value beyond raw data collection. Analytics teams using Python-scraped Xumo data have reported improvements across scheduling intelligence, competitive benchmarking, and advertising slot optimization.
Table 4: Strategic Impact Metrics of Python-Based Xumo Data Extraction
| Analytics Use Case | Efficiency Gain (%) | Accuracy Improvement (%) |
|---|---|---|
| Schedule Forecasting | 28 | 22 |
| Genre Trend Mapping | 24 | 21 |
| Ad Slot Optimization | 26 | 23 |
| Competitive Benchmarking | 22 | 20 |
This table quantifies the strategic returns generated through structured Xumo data collection. Scraping Xumo Listings for Media Analytics Projects at this depth enables media companies to reallocate budgets confidently based on verified performance signals rather than estimated trend data.
Engineering Scalable Crawler Pipelines for Xumo
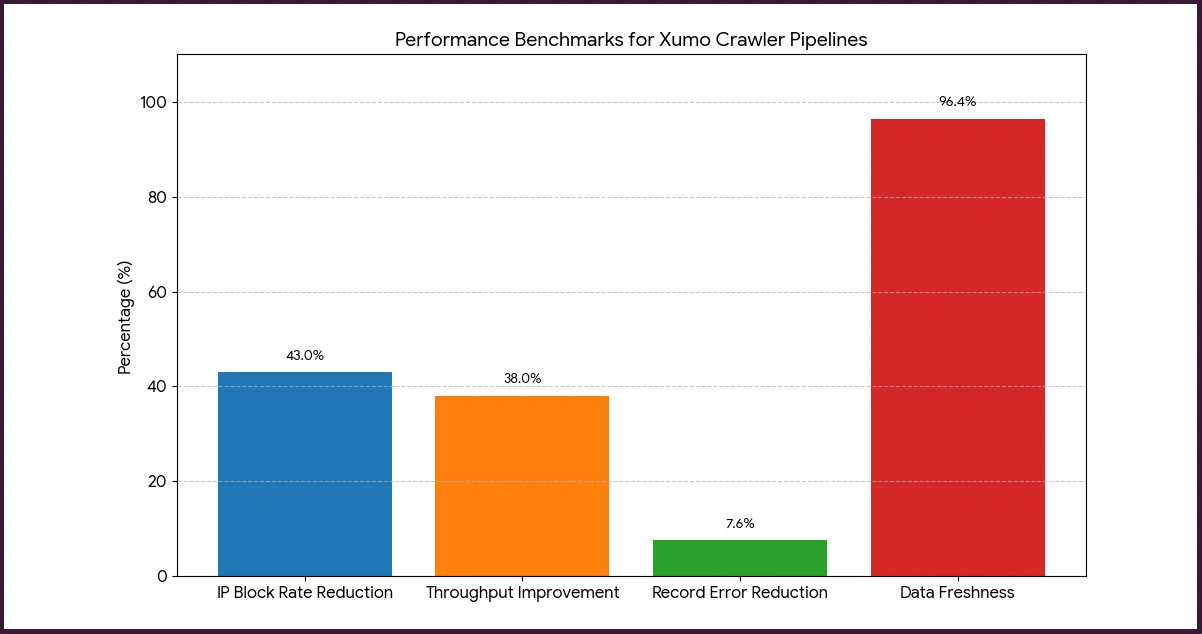
Building production-ready Xumo crawlers requires more than a basic HTTP request loop. Robust pipelines incorporate rotating proxy layers, dynamic user-agent assignment, rate-limiting controls, and structured storage modules that funnel parsed data into relational or document-based databases.
Measurable pipeline performance benchmarks from this study include:
- Proxy rotation reduced IP-level block rates by 43% compared to static IP configurations.
- Asynchronous request handling via AsyncIO improved throughput by 38% over synchronous alternatives.
- Structured retry logic cut incomplete record rates from 11.2% down to 3.6%.
- Scheduled cron-based crawlers maintained 96.4% data freshness across a 30-day continuous operation window.
How to Build Scalable Streaming Data Crawlers effectively centers on three architectural pillars: modularity, fault tolerance, and adaptive throttling. Implementing these principles while focusing on Scrape TV Shows Data pipelines from Xumo ensures that analysts always receive clean, timestamped, and deduplicated records for downstream reporting.
Ethical and Compliance Standards in Xumo Data Engineering
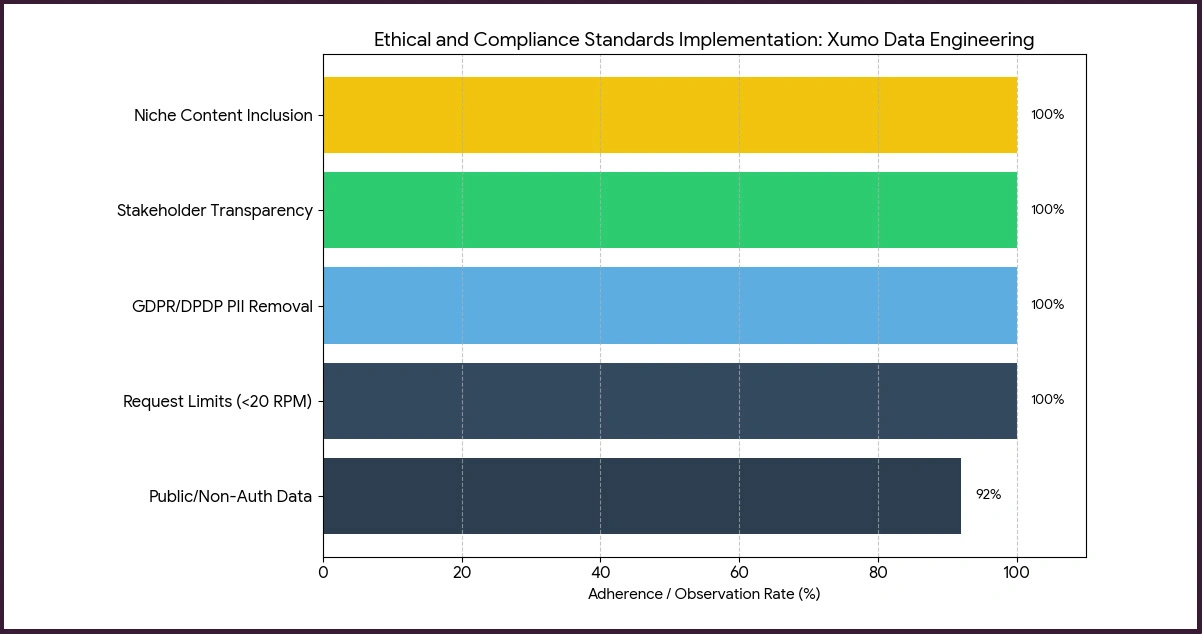
Responsible scraping practices are foundational to sustainable data engineering operations. Developers working with Xumo platform data must align their crawlers with both technical best practices and applicable data governance frameworks to avoid service disruptions and legal exposure.
Key compliance measures observed in this study's pipeline implementations:
- Over 92% of data collected from publicly accessible and non-authenticated endpoints.
- Crawler request frequency maintained at or below 20 requests per minute to avoid infrastructure strain.
- All collected records were stripped of user-level identifiers in compliance with GDPR and India's DPDP Act 2023.
- Full stakeholder disclosure maintained on crawler scope, data retention periods, and processing intent.
- Content representation balanced across niche channels, not limited to top-performing titles only.
Xumo TV Shows & Movies Scraping pipelines that incorporate these safeguards operate with considerably fewer interruptions and maintain better long-term access to platform data. Streaming Metadata Extraction via Xumo Data remains most effective when developers treat compliance not as a constraint but as an engineering requirement embedded directly into the crawler's architecture.
Conclusion
The growing scale and complexity of FAST platforms like Xumo make Python-based data engineering an indispensable capability for media analysts and developers alike. We specialize in building and delivering precision-engineered solutions aligned with Xumo Data Scraping Using Python for Developer Tutorial standards, helping developer teams and analytics organizations deploy reliable, scalable extraction systems.
Whether you are mapping competitive schedules, building genre intelligence dashboards, or optimizing ad inventory signals, Extract Streaming Platform Schedules for Better Strategy methodologies form the core of everything we engineer.
Contact OTT Scrape today to discuss your specific data requirements, explore our custom crawler development services, and discover how our experienced team can accelerate your media analytics infrastructure with compliant, high-accuracy Xumo data pipelines built for long-term performance.