
Introduction
In today's data-driven world, the ability to extract links from websites efficiently is paramount. Whether it's for market research, competitive analysis, or content aggregation, web scraping plays a crucial role in gathering data from the vast expanse of the internet. In this comprehensive guide, we'll learn to extract links from websites using website link scraping techniques with Python, BeautifulSoup, and Scrapy and how you can build and leverage your own link scraper.
Understand Website Link Scraping
Website link scraping, also referred to as URL scraping or link extraction, involves the extraction of hyperlinks from web pages. These hyperlinks, commonly known as URLs, direct users to other web pages, resources, or files. This process provides valuable insights into website structures, content relationships, and overall connectivity within the web.
Organizations can gain a deeper understanding of online content's interconnected nature by using a crawler to extract websites links to extract links from websites. A websites links scraper is instrumental in collecting URLs from various sources, enabling researchers, marketers, and analysts to analyze website content, identify trends, and explore relationships between different web pages.
Whether for SEO analysis, content aggregation, or academic research, a URL scraper is a versatile tool that facilitates the extraction of website links. This process lets users gather comprehensive datasets and glean actionable insights to inform decision-making processes. With the ability to extract links from websites efficiently, organizations can stay competitive in the digital landscape and uncover hidden opportunities for growth and optimization.
Building a Website Link Scraper
Embarking on the journey of building a websites links scraper is a testament to your power as a developer, data analyst, or researcher. With the mighty trio of Python, BeautifulSoup, and Scrapy in your hands, you have the tools to create a robust URL scraper that can efficiently and accurately extract links from a myriad of web sources.
Here's a comprehensive guide to building your websites links scraper:
Define Your Target Website: Your role as a developer, data analyst, or researcher starts by identifying the website from which you want to extract links from websites. Understanding the target site's structure is crucial for effective scraping, whether it's a blog, news site, e-commerce platform, or any other web resource.
Choose Your Scraping Tool: Depending on your requirements and preferences, select a suitable web scraping framework or library. BeautifulSoup is a popular choice for HTML parsing, while Scrapy offers a more comprehensive solution for building web crawlers.
Set Up Your Environment: Once you've chosen your scraping tool, ensure your development environment is configured correctly. Install Python and any necessary libraries, such as requests, BeautifulSoup, and Scrapy, to enable seamless development.
Write Your Scraper Code: Now that your environment is set up, it's time to start writing your scraper code. Develop functions to fetch web pages, parse HTML content, and extract links based on specific criteria. Utilize BeautifulSoup's intuitive syntax or Scrapy's robust framework to streamline the scraping process.
Test Your Scraper: Before deploying your scraper, it's essential to test its functionality thoroughly. Test it on sample web pages to ensure it accurately extracts the desired links and gracefully handles edge cases. This step helps identify and resolve potential issues before deploying your scraper in a production environment.
Deploy Your Scraper: Once your scraper functions correctly, deploy it to your preferred environment. You can run your scraper locally or deploy it to a cloud-based platform for automated scraping. Schedule your scraper to run periodically to keep your link database up-to-date with the latest information.
Building a website link scraper offers numerous benefits across various industries and domains. Whether you're conducting SEO analysis, content aggregation, or academic research, a well-designed websites links scraper can provide valuable insights and opportunities for analysis. By following this step-by-step guide and leveraging the power of Python, BeautifulSoup, and Scrapy, you can build a robust scraper capable of extracting links from websites efficiently and accurately.
Applications of Website Link Scraping

Website link scraping offers a wide range of applications across diverse industries and domains, making it a valuable tool for various purposes:
SEO Analysis: Website link scraping enables SEO professionals to conduct comprehensive backlink analysis, allowing them to assess the quality and quantity of inbound links to a website. This information helps identify link-building opportunities, track competitor link strategies, and optimize link profiles for improved search engine rankings.
Content Aggregation: Media companies and aggregators can leverage link scraping to gather news articles, blog posts, and other web content from multiple sources. This allows them to curate relevant content for their audience, syndicate content across platforms, and stay updated on the latest trends and developments in their industry.
Market Research: Businesses can use link scraping to extract product links from e-commerce websites, enabling them to monitor pricing trends, analyze product availability, and gather competitive intelligence. This information helps businesses make informed decisions regarding pricing strategies, product offerings, and market positioning.
Academic Research: Researchers can employ link scraping to collect data for academic studies, such as analyzing citation networks, tracking references in scholarly articles, and studying the dissemination of information across various online platforms. This enables them to conduct in-depth research, identify patterns and trends, and contribute to advancing knowledge in their field.
Legal Compliance: Compliance professionals can utilize link scraping to monitor websites for copyright infringement, unauthorized content distribution, or other legal violations. By automatically extracting links from target websites, they can identify instances of unauthorized content usage, track down copyright infringements, and take appropriate legal action to protect intellectual property rights.
Website link scraping is a versatile tool that offers valuable insights and opportunities for analysis across various industries and domains. By leveraging link scraping tools such as crawler to extract websites links or extract links from websites, businesses, researchers, and compliance professionals can gain a competitive edge, stay informed, and ensure legal compliance in the digital age.
Best Practices for Website Link Scraping
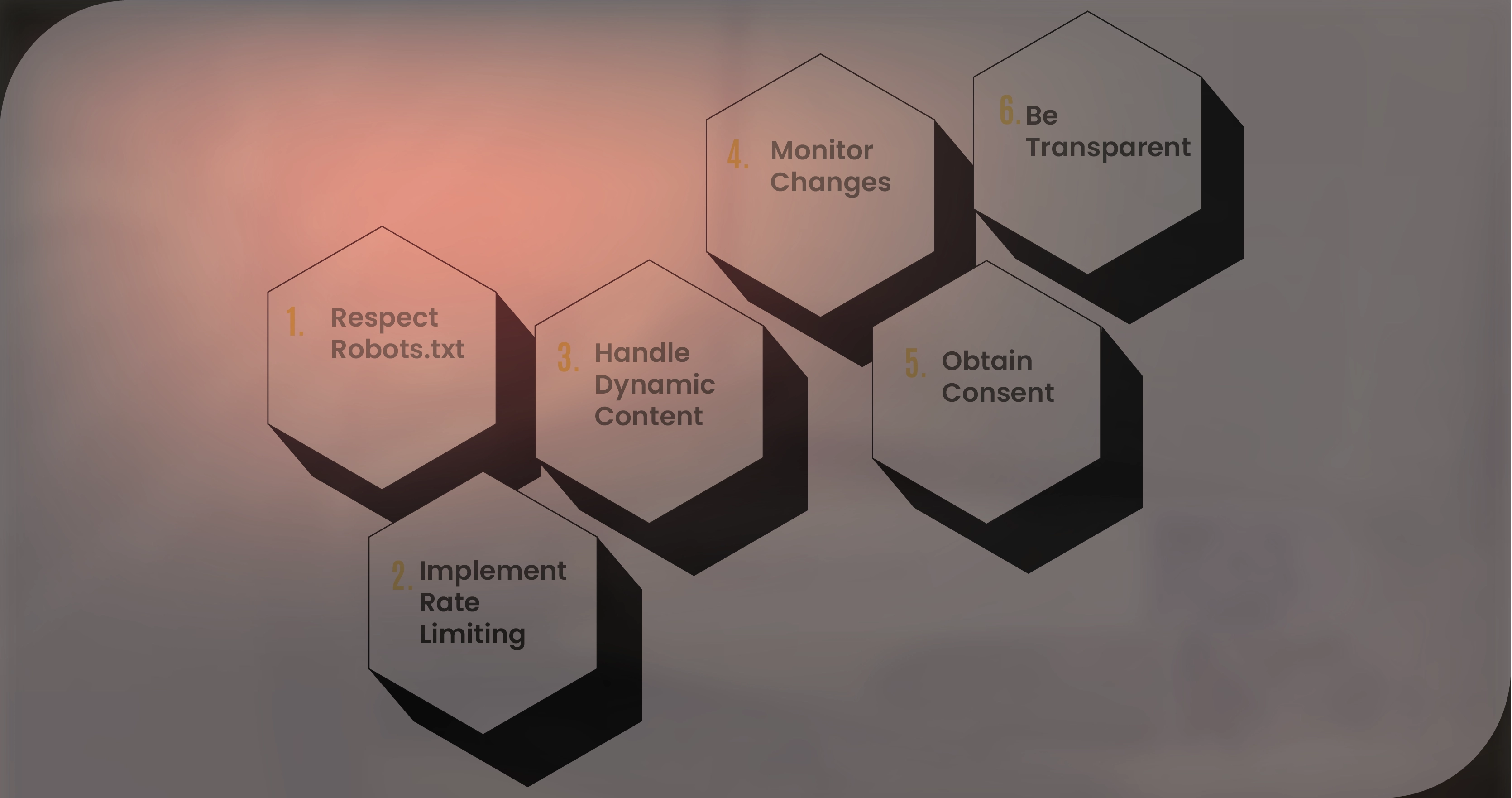
When engaging in website link scraping, it's crucial to follow ethical and legal guidelines to ensure a smooth and compliant scraping process:
Respect Robots.txt: Always check the target website's robots.txt file to determine if web scraping is allowed. Adhere to any rules or directives outlined in the file to maintain good scraping practices.
Implement Rate Limiting: To avoid overloading the target website's servers and mitigate the risk of being flagged or blocked, implement rate limiting in your scraping process. Limit the frequency of requests to ensure responsible scraping behavior.
Handle Dynamic Content: Many websites utilize JavaScript or AJAX to load content dynamically. Ensure that your scraper is capable of handling dynamic content effectively to extract links from the target website accurately.
Monitor Changes: Websites frequently update their content and structure, which can impact the scraping process. Regularly monitor for changes in the website's layout or structure and adjust your scraper accordingly to maintain its effectiveness.
Obtain Consent: If you're scraping personal or sensitive data, ensure you have the necessary consent or legal authorization. Respect user privacy and data protection laws by obtaining explicit consent before scraping sensitive information.
Be Transparent: If you're scraping publicly available data for research or analysis purposes, be transparent about your methods and intentions. Communicate the purpose of your scraping activities and ensure you're not violating any terms of service or legal agreements.
By adhering to these best practices, you can conduct website link scraping in a responsible and compliant manner, minimizing the risk of encountering legal issues or disruptions to your scraping efforts.
Conclusion
Unlock the potential of web data with OTT Scrape's website link scraping service. Our websites links scraper provides valuable insights for market research, competitor monitoring, or academic studies. We ensure responsible scraping practices by adhering to ethical guidelines and best practices. Our advanced scraping technology enables you to extract valuable information from the web efficiently and effectively. Gain a competitive edge and make informed decisions with OTT Scrape's website link scraping service. Use the power of web data and elevate your strategies today!