
Introduction
In the ever-expanding world of Over-the-Top (OTT) streaming platforms, Shudder has established itself as a premier destination for horror enthusiasts. With its extensive library of spine-chilling movies and original content, Shudder provides a unique viewing experience for subscribers. Behind the scenes, Shudder movie datasets hold a wealth of valuable information that can provide deep insights into viewer behavior, content preferences, and industry trends. In this comprehensive guide, we'll delve into the process to Scrape Shudder Movie Streaming Data, along with its significance in shaping the OTT landscape.
Understanding Shudder

Shudder is a leading Over-the-Top (OTT) streaming platform specializing in horror content, offering a diverse library of movies, series, and originals. Catering to horror enthusiasts, Shudder provides a curated selection of spine-chilling titles spanning various subgenres. Launched in 2015, Shudder has gained popularity for its exclusive horror offerings, including cult classics, indie gems, and original productions. With a focus on quality over quantity, Shudder delivers a unique viewing experience for subscribers, fostering a vibrant community of horror fans. As a dedicated platform for horror content, Shudder continues to expand its library and influence in the streaming industry.
Understanding Shudder Movie Datasets
Shudder movie datasets encompass a wide range of metadata associated with the platform's movie offerings. This includes details such as movie titles, genres, release dates, cast and crew information, ratings, user reviews, and more. These datasets serve as a treasure trove of information, offering valuable insights into the horror genre's popularity, viewer engagement, and content trends.
The Importance of Shudder Movie Data Collection
Shudder movie data collection plays a pivotal role in the strategic decision-making process for both the platform itself and industry analysts seeking to understand viewer behavior and content trends. With the rise of Over-the-Top (OTT) streaming platforms like Shudder, data has become an invaluable asset for shaping content strategy, enhancing user experience, and driving business growth.
Understanding Viewer Preferences
Shudder movie data sets provide crucial insights into viewer preferences within the horror genre. By systematically collecting data on the platform's movie offerings, analysts can discern patterns and trends regarding which types of horror content resonate most with viewers. This information helps content creators and distributors tailor their offerings to match audience preferences, thereby increasing viewer engagement and retention.
Content Curation and Recommendation
Effective content curation and recommendation systems rely heavily on data-driven insights. By analyzing Shudder movie data, platform administrators can identify popular titles, trending genres, and emerging content trends. This enables them to curate a diverse and engaging selection of horror movies that appeals to a wide range of viewers. Additionally, personalized recommendations based on viewer preferences can enhance the user experience and drive continued usage of the platform.
Strategic Decision-Making
Shudder movie data collection informs strategic decision-making processes for the platform, including content acquisition, licensing agreements, and original productions. By analyzing viewer engagement metrics and content performance indicators, stakeholders can identify high-performing titles and allocate resources accordingly. This ensures that the platform offers a compelling and competitive selection of horror content, maintaining its appeal to existing subscribers and attracting new ones.
Industry Insights and Trends
Shudder movie data sets also provide valuable insights for industry analysts seeking to understand broader trends within the OTT streaming landscape. By comparing Shudder's content library with that of other platforms and tracking viewer behavior over time, analysts can identify emerging content trends, market opportunities, and competitive threats. This information helps stakeholders make informed decisions about content strategy, audience targeting, and marketing efforts.
Techniques for Shudder Movie Data Extraction
Shudder movie data extraction involves systematic gathering of metadata and relevant information from Shudder's extensive library of horror movies. To effectively extract Shudder movie data, various techniques can be employed, including web scraping, API access, and manual data entry.
Web Scraping
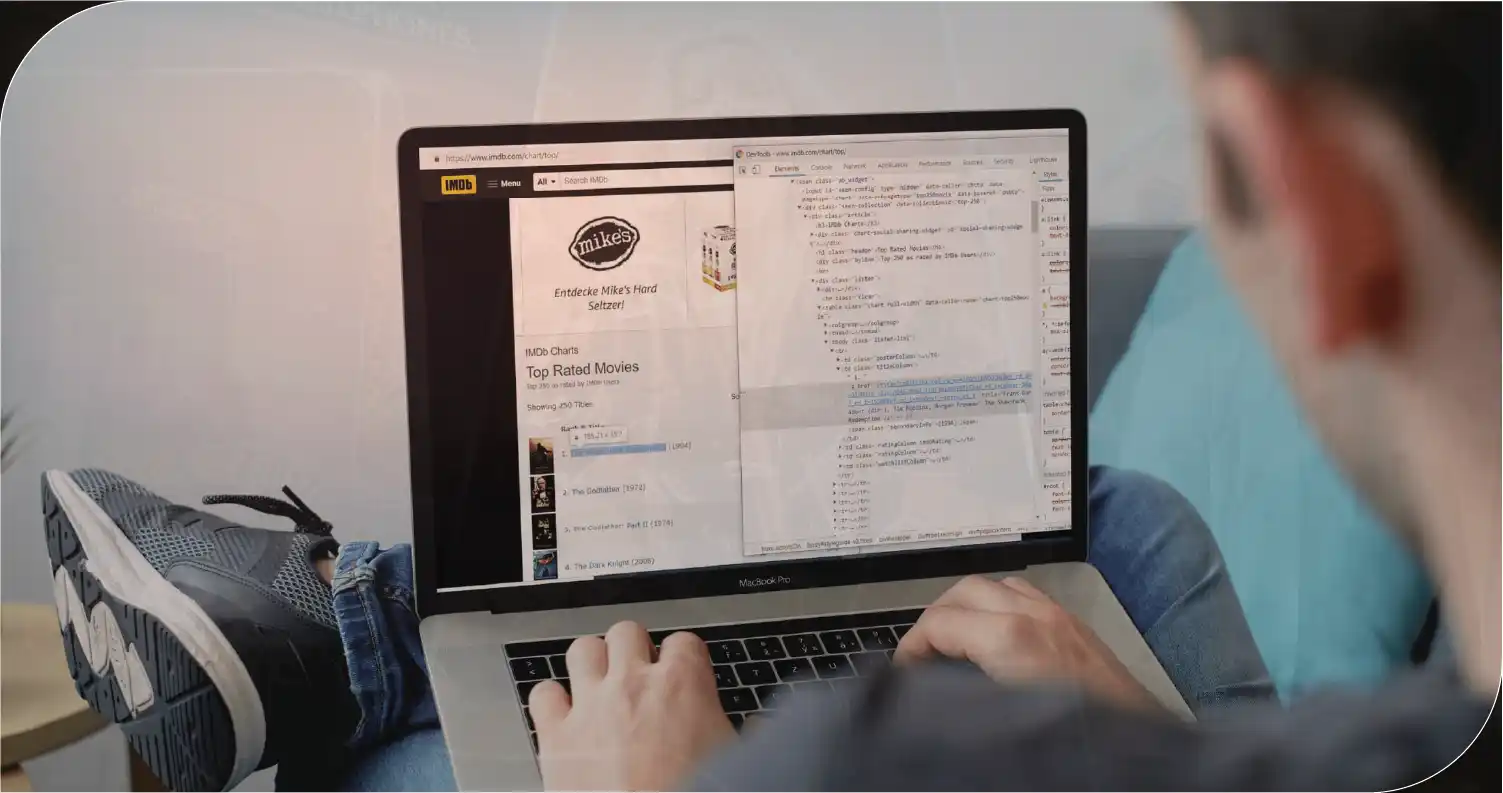
Web scraping is a widely used technique for Shudder movie data extraction, enabling automated collection of data from Shudder's website. Python-based libraries such as BeautifulSoup and Scrapy are commonly employed for web scraping tasks. Analysts write scripts to navigate Shudder's website and extract relevant data elements such as movie titles, genres, release dates, cast information, ratings, and user reviews. By automating the data extraction process, web scraping enables efficient collection of large volumes of Shudder movie data for analysis.
API Access

Some streaming platforms, including Shudder, offer Application Programming Interfaces (APIs) that provide programmatic access to their data. API access allows developers to retrieve structured data directly from the platform's servers without the need for web scraping. By leveraging Shudder's API, analysts can access a wide range of movie metadata, including details on titles, genres, release dates, cast and crew information, ratings, and more. This method offers a more efficient and reliable approach to Shudder movie data extraction compared to web scraping.
Manual Data Entry

In cases where web scraping or API access is not feasible, manual data entry may be employed as an alternative method for Shudder movie data extraction. While more time-consuming and labor-intensive, manual data entry involves manually inputting data elements such as movie titles, genres, release dates, and other relevant information into a spreadsheet or database for further analysis. This approach may be suitable for smaller-scale data collection efforts or when access to automated extraction methods is limited.
Challenges and Considerations
While Shudder movie data collection holds immense potential for generating valuable insights, several challenges and considerations must be addressed to ensure its successful implementation.
Legal and Ethical Considerations
One of the primary challenges of Shudder movie data collection revolves around legal and ethical considerations. Streaming platforms like Shudder have terms of service that dictate how their data can be accessed and used. Violating these terms can lead to legal repercussions, including legal action or termination of access to the platform. It is essential for data collectors to familiarize themselves with Shudder's terms of service and adhere to them strictly during data collection.
Data Quality Issues
Another challenge in working with Shudder movie data sets is ensuring data quality. While web scraping and API access can provide access to a wealth of data, the quality of that data may vary. Inaccurate or incomplete data can impact the reliability of analysis results and lead to incorrect conclusions. Data collectors must implement quality assurance measures to verify the accuracy and completeness of the collected data before using it for analysis.
Platform Changes and Updates
Streaming platforms like Shudder frequently update their interfaces, algorithms, and content libraries, which can impact data collection efforts. Changes in the platform's structure or policies may require adjustments to data collection methods or scripts. Data collectors must stay vigilant and monitor for platform changes to ensure that their data collection processes remain effective and up-to-date.
User Privacy
Respecting user privacy is a critical consideration when collecting and analyzing Shudder movie data. Collecting personally identifiable information or sensitive data without user consent is unethical and may violate privacy regulations. Data collectors must ensure that they only collect and use data in compliance with applicable privacy laws and regulations, such as the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States.
Conclusion
Shudder movie datasets are a treasure trove of insights for industry stakeholders navigating the dynamic OTT landscape. OTT Scrape specializes in leveraging web scraping techniques for Shudder movie data collection and extraction. Unlock actionable insights to shape your content strategy, target your audience effectively, and optimize your marketing efforts. As the OTT industry evolves, trust OTT Scrape to provide you with the crucial data insights you need to stay ahead of the curve. Contact us today to harness the power of Shudder movie datasets for your business success.